
Browse Source
docs: add public data analysis example (#2102)
* docs: add public data analysis example Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * add visualization part Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * add a newline Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * update doc goals and explanations Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * add usecases section Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * add influxdb to chart details Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * add English version Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * fix markdown lint errors Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> * update cn part * some wording updates * docs: add public data analysis example Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * add visualization part Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * add a newline Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * update doc goals and explanations Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * add usecases section Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * add influxdb to chart details Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * add English version Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * fix markdown lint errors Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * update cn part Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> * some wording updates Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> --------- Signed-off-by: xjasonlyu <xjasonlyu@gmail.com> Signed-off-by: LenaLenaPan <hilena.pan@gmail.com> Co-authored-by: LenaLenaPan <hilena.pan@gmail.com>
 Jason Lyu
Jason Lyu
6 tập tin đã thay đổi với 562 bổ sung và 0 xóa
+ 290
- 0
docs/en_US/usecases/public_data_analysis.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
docs/en_US/usecases/resources/formula.webp
{kind=link}
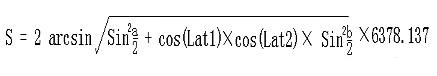
BIN
docs/en_US/usecases/resources/public-data-chart.png
{kind=link}

+ 272
- 0
docs/zh_CN/usecases/public_data_analysis.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
docs/zh_CN/usecases/resources/formula.webp
{kind=link}
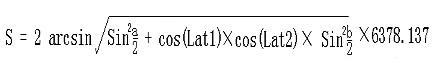
BIN
docs/zh_CN/usecases/resources/public-data-chart.png
{kind=link}
